

When building AI systems, early choices – like selecting frameworks, designing data pipelines, or defining APIs – often feel temporary but can become permanent obstacles. These decisions, if rushed, create technical debt, scalability issues, and integration challenges that are costly and disruptive to fix later.
Key issues include:
- Technical Debt: Quick framework choices lead to tangled dependencies and expensive maintenance.
- Scalability Problems: Poorly planned data pipelines evolve into unmanageable systems.
- Legacy Integration: Hidden dependencies in older systems complicate upgrades.
To avoid these problems:
- Audit Dependencies: Identify risks and weak points early.
- Modular Design: Break systems into smaller, independent components.
- Plan and Test: Dedicate time upfront to reduce future costs.
Fixing architecture after deployment can cost 15–100x more than addressing it during design. Thoughtful early planning saves time, money, and effort in the long run.
AI’s Silent Killer: Technical Debt & the Hidden Costs of Bad Data
Why AI Architecture Decisions Are Difficult to Reverse
Reversing AI architecture decisions is no small feat. The challenges stem from a mix of technical debt, scalability issues in early data pipeline design, and the complex integration of legacy systems. Over time, these factors grow more tangled, driving up both complexity and costs.
Technical Debt from Quick Framework Choices
One major hurdle is technical debt. When frameworks are chosen hastily, they create a web of dependencies where even a small change can ripple across the entire system. Machine learning systems often follow the principle of "Changing Anything Changes Everything", where decisions about frameworks, data distributions, feature sets, and hyperparameters are so interconnected that isolating a single change becomes nearly impossible [4].
Adding to the problem is the rise of "glue code" – extra code needed to make general-purpose AI frameworks fit specific use cases. This code often overshadows the core AI logic, making maintenance a nightmare. Compounding this is what experts call "comprehension debt", where AI-generated code is poorly understood by human teams.
"AI can’t see what your code base is like, so it can’t adhere to the way things have been done" [6].
Fixing bugs in AI-generated code can be up to three or four times more expensive than addressing issues in human-written code, thanks to a "context gap" [7]. In fact, environments heavily reliant on AI-generated code have seen code rewrites increase by 9% annually, with technical debt adding an estimated 10–20% extra cost to new projects [7].
Scalability Problems in Early Data Pipeline Design
Decisions made during the early stages of building data pipelines can create long-term challenges. A common issue is the "Pipeline Jungle", where what starts as a simple data flow evolves into a convoluted system that’s nearly impossible to manage [4]. This complexity often consumes significant engineering resources.
One notable pitfall is the "shared data trap", where multiple services rely on a single, massive database.
"If your new microservices all talk to that same database, you haven’t migrated ANYTHING. You just put a new coat of paint on the same old problem" [8].
This setup can result in a "distributed monolith" – a system where components are so tightly interconnected that independent scaling becomes impossible, effectively bottlenecking the entire architecture.
Real-world examples highlight the stakes. REWE Digital, for instance, transitioned from a monolithic system to over 270 microservices, requiring their development team to grow from 2 autonomous teams to 48 [8]. Similarly, Amazon Prime Video‘s shift to 12 core microservices led to a 30% speed boost and the ability to process 100,000 transactions per second without downtime [8].
Integration Difficulties with Legacy or Disconnected Systems
Legacy systems introduce another layer of complexity. These systems often harbor "undeclared consumers" – hidden dependencies that silently rely on AI model outputs. When the AI architecture is modified, these dependencies can break, causing widespread failures [3]. Interestingly, the actual machine learning code typically makes up only a small portion of the overall system, with the majority dedicated to integration, data collection, and infrastructure [4].
Data dependency debt further complicates matters. AI models often become tightly linked to the specific data distributions of legacy systems. If these systems have poorly integrated or mismatched data models, the AI architecture inherits these flaws. Nearly half of surveyed banks, for example, still struggle with disparate data models despite modernization efforts [5].
"Machine learning modules only represent a small fraction of the code contained within machine learning-enabled systems, and their integration is often challenging and a source of quality concerns" [4].
Reversing an architectural decision in such a scenario isn’t as simple as swapping one component for another. It often requires reworking an entire network of interconnected systems. Together, these challenges illustrate why undoing early AI architecture choices is such a daunting task.
How to Avoid Irreversible AI Architecture Mistakes
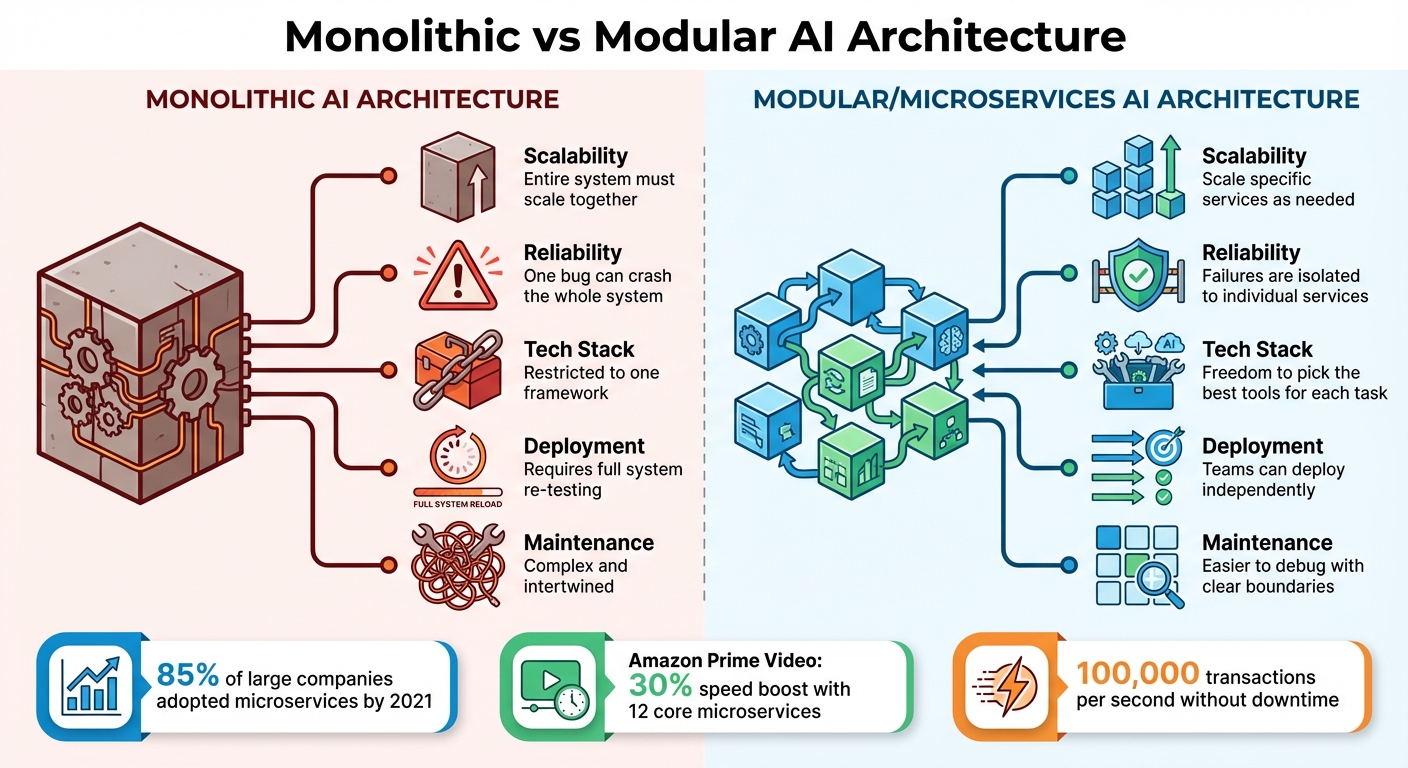
Monolithic vs Modular AI Architecture Comparison
Steering clear of irreversible mistakes in AI architecture starts with careful planning and smart decisions early on. By focusing on these strategies, you can build systems that are flexible enough to evolve with future needs.
Map Dependencies and Audit Risks
Before committing to any framework or tool, it’s essential to perform a Failure Mode Analysis (FMA). This process helps pinpoint critical failure points in your system. AI systems often suffer from tightly linked components, where one change can unexpectedly disrupt everything else [3]. Identifying hidden feedback loops and undeclared data dependencies early can save you from skyrocketing maintenance costs later.
A survey of financial institutions found that while 70% had a roadmap for modern data architecture, nearly half still struggled with mismatched data models [5]. This gap between planning and execution underlines the importance of auditing risks upfront. When integrating with older systems, consider using an Anti-Corruption Layer (ACL). Think of it as a "translator" that converts messy legacy data into clean, usable formats, ensuring that outdated habits don’t corrupt your new AI architecture [8].
For example, a large German bank used a proven reference data architecture and cut the time needed to define its architectural blueprint from over three months to just four weeks [5]. This allowed the CIO to start data ingestion within a month, conserving both time and resources.
Once risks are mapped, modularity becomes the next critical step to fortify your system.
Build Modular and Scalable Architecture
A modular design breaks down complex systems into smaller, independent components. Often referred to as "compound AI systems", this approach lets you develop, deploy, and scale each part separately [11].
"The true power of a microservices architecture lies in decoupling and reducing the dependencies between components so they can operate and evolve independently." – AWS Prescriptive Guidance [11]
By 2021, 85% of large companies had adopted microservices to address scaling and deployment challenges [8]. The benefits are evident. For instance, Amazon Prime Video shifted from a monolithic setup to 12 core microservices, boosting service speed by 30% and enabling it to handle 100,000 transactions per second without downtime [8].
Here’s a quick comparison of monolithic versus modular architectures:
| Attribute | Monolithic AI Architecture | Modular/Microservices AI Architecture |
|---|---|---|
| Scalability | Entire system must scale together | Scale specific services as needed |
| Reliability | One bug can crash the whole system | Failures are isolated to individual services |
| Tech Stack | Restricted to one framework | Freedom to pick the best tools for each task |
| Deployment | Requires full system re-testing | Teams can deploy independently |
| Maintenance | Complex and intertwined | Easier to debug with clear boundaries |
To avoid creating a "distributed monolith", where services remain tangled through a shared database, adopt a "database per service" approach. Each microservice should manage its own data. For AI-specific applications, centralize access to large language models using an AI gateway. This way, you can switch models with a simple configuration change instead of rewriting core logic [11].
After addressing modularity, the next key step is allocating time for thoughtful planning and rigorous testing.
Allocate Dedicated Time for Planning and Testing
Skipping the planning phase often leads to costly overhauls. Set aside 15–20% of your project time for designing and testing the architecture [11]. This upfront investment helps avoid expensive rewrites and long-term technical debt.
Scaling large language models (LLMs) is a prime example of why early planning matters. Resource needs for LLMs increase non-linearly [13]. Without proper preparation, user growth can lead to unsustainable costs. In fact, 95% of corporate generative AI pilots fail to deliver expected financial benefits, often due to poorly designed data and workflows [14].
"A migration isn’t a single project with a start and end date. It’s a continuous process of chipping away at the old system while building the new one." – 42 Coffee Cups [8]
Planning also includes designing for human-in-the-loop workflows. For high-stakes decisions or irreversible actions, build systems that pause and seek human approval before proceeding [13] [14]. For instance, in 2023, Deloitte Australia faced backlash and had to repay part of its $440,000 fee to the Australian government after a generative AI-produced report contained numerous errors and false references [14]. Such failures could have been avoided with better architecture planning.
Document every architectural choice in Architecture Decision Records (ADRs) to ensure you don’t revisit the same issues repeatedly [12]. Treat architecture as an ongoing commitment rather than a one-time task, and you’ll create AI systems that grow and adapt alongside your business.
sbb-itb-51b9a02
How AlterSquare‘s I.D.E.A.L. Framework Builds Flexible AI Systems
AlterSquare’s I.D.E.A.L. Framework emphasizes flexibility at every stage of the AI lifecycle, ensuring systems can adapt and scale over time. By focusing on early planning and modular design, this framework avoids irreversible decisions and keeps systems open to evolution. Instead of rushing to deployment, it prioritizes reversible choices, allowing for adjustments as needs and technologies change.
Phased Discovery and Testing
The discovery phase is all about validating architecture choices before scaling up. AlterSquare avoids committing to a single framework or model too early, instead promoting a process where models and configurations are thoroughly tested from Proof of Concept (PoC) to preproduction [11]. This approach ensures flexibility, reducing the risk of costly rewrites later on [1].
Prototyping during this phase uncovers potential integration issues and hidden dependencies before they become locked into production. By experimenting with different architectural patterns, teams can avoid rigid designs that might struggle to accommodate new AI models or evolving business needs.
Once early risks are identified, the system’s adaptability is further refined through agile development.
Agile Development for Flexibility
AlterSquare’s agile approach breaks down monolithic AI applications into smaller, independent microservices, each handling a specific function [11]. This modular design allows for continuous iteration during each sprint.
"In 2025, the winners aren’t those who simply call a large model; they are the teams that design robust systems around the model." – Sealos [16]
Agile sprints give teams the freedom to experiment with various AI providers, swap models when needed, and tweak prompts – all without disrupting the entire system. This iterative process ensures the architecture can keep pace with rapid changes in AI models, provider pricing structures, or feature deprecations [9].
Post-Launch Support and Ongoing Improvement
The I.D.E.A.L. Framework doesn’t stop at launch. AlterSquare uses domain-specific interfaces to abstract AI providers like OpenAI, Anthropic, and AWS [9]. This abstraction allows teams to switch between models as they evolve or as pricing changes, without having to overhaul core business logic.
Automated monitoring systems play a key role in maintaining system accuracy by detecting model drift and triggering evaluations [10][15]. This proactive approach ensures the system adapts to changing conditions. For example, maintaining "first token" latency under two seconds is a key performance benchmark for delivering a smooth AI experience [16]. AlterSquare achieves this through centralized AI gateways, which provide unified APIs for multiple large language models (LLMs). These gateways also enhance observability, security, and cost management, keeping everything streamlined [11].
Conclusion
By the third year of development, the core decisions shaping an AI system’s architecture are usually set in stone, making any changes extremely costly. Fixing issues after deployment can cost anywhere from 15 to 100 times more than addressing them during the design phase. For fundamental architecture changes, those costs can skyrocket even further – up to tenfold [2]. This often forces teams to spend as much as 80% of their time putting out fires instead of focusing on innovation [2].
"The decisions made today become the constraints lived with tomorrow, the technical debt serviced next year, the complete rewrite forced in five years." – Igor Maric, Software Architect [2]
Understanding the gravity of these decisions is the first step toward designing systems that stand the test of time. To avoid locking yourself into costly constraints, it’s crucial to differentiate between irreversible "one-way door" decisions – like selecting a database or defining core domain models – and reversible "two-way door" decisions, such as choosing a UI framework [2]. Modular designs and thorough dependency audits, as mentioned earlier, are key strategies for mitigating these risks. For example, separating business logic from AI providers enables you to swap out models through simple configuration changes instead of overhauling the entire system [9] [11].
Investing time upfront for architectural planning pays off in the long run. Teams that thrive often dedicate around 20% of their capacity to improving their architecture and 10% to exploring new possibilities [2]. This proactive approach helps avoid the "refactor later" mindset, which can lead to expensive rewrites when the system’s limitations become a roadblock to growth.
FAQs
Why is technical debt such a challenge in AI system design?
Technical debt in designing AI systems can quickly spiral into a significant challenge. Early decisions – like cutting corners or rushing through development – often result in long-term headaches. For instance, poorly designed data pipelines, dependence on specific frameworks, or outdated architecture can make systems harder to scale, more expensive to maintain, and increasingly fragile as they grow.
If left unchecked, technical debt can lead to serious problems, such as reduced system reliability, limited adaptability, and rising operational costs. Over time, these issues can stifle progress and make it tough for organizations to update their AI systems to meet new requirements or handle evolving environments. Tackling technical debt early on is crucial to building systems that are scalable, resilient, and ready to handle future challenges.
How does modular design help avoid irreversible AI architecture challenges?
Modular design tackles potential roadblocks in AI architecture by dividing systems into smaller, independent components – like data processing, model training, and monitoring. This approach ensures that teams can update or replace specific parts without disrupting the entire system, maintaining both flexibility and scalability as requirements shift.
By keeping components separate, organizations can sidestep issues like technical debt and system inflexibility. It becomes much simpler to switch frameworks or refine pipelines without needing to rewrite everything from scratch. This structure is essential for keeping AI systems ready for the fast pace of technological advancements. Beyond minimizing risks, modular design also lays the groundwork for sustained growth and innovation.
How can legacy systems be integrated effectively into AI projects?
Integrating legacy systems into AI projects can feel like navigating a maze, but with the right strategies, it’s manageable. One smart move is breaking down those bulky, monolithic systems into modular components – think microservices. Why? It simplifies the process of adding AI features and lets you upgrade or replace parts gradually without throwing the entire system into chaos.
Another helpful tactic is embracing a flexible architecture. This means building temporary solutions that can be swapped out as the system evolves. It’s a balancing act – meeting immediate needs while keeping an eye on future growth. On top of that, sticking to solid data architecture principles and steering clear of shortcuts that pile up technical debt can save you from expensive headaches down the road.
By prioritizing modular designs, planning phased upgrades, and staying disciplined, organizations can smoothly integrate AI into older systems while staying ready for what’s next.






Leave a Reply