

AI systems are changing the way we approach software development, but they come with hidden costs. Here’s the deal: AI introduces new types of technical debt that make systems harder to maintain, debug, and scale. Unlike traditional software, AI’s reliance on data and complex algorithms creates unique challenges like:
- Epistemic debt: When AI generates code too complex for teams to understand, making changes risky.
- Data dependencies: AI models degrade over time as real-world data shifts, leading to performance issues.
- Black box problems: Opaque AI models make debugging and compliance difficult.
- Integration hurdles: Legacy systems struggle to handle AI’s demands, creating inefficiencies and bottlenecks.
The costs of ignoring these issues are massive – companies face higher maintenance expenses, compliance risks, and system failures. For example, Southwest Airlines‘ 2022 meltdown cost $750 million, partly due to outdated systems. To manage AI-related debt, businesses need structured strategies like modular design, automated testing, and regular monitoring.
Key takeaway: AI speeds up development but can lead to long-term liabilities if not managed carefully. Addressing technical debt early ensures systems remain stable and scalable while avoiding costly failures.
Black Box Algorithms and Interpretability Issues
Why Opaque Models Create Problems
The lack of transparency in AI systems creates significant challenges, particularly as these systems scale. One major issue is the accumulation of epistemic debt – a situation where the behavior of a system becomes disconnected from the team’s understanding of it. Unlike traditional technical debt, where shortcuts are taken knowingly, epistemic debt arises when teams deploy code they don’t fully grasp. This leads to systems that work, but no one can explain how or why.
Opacity in AI appears in several forms. Essential opacity refers to the inability to trace the logic behind a decision. You might see the outcome, but the reasoning remains hidden. Even more concerning is verification opacity, where tests confirm the AI’s interpretation of requirements but fail to validate the actual business needs. This can result in issues like the "green CI trap", where automated tests pass, but the system fails in production, creating significant maintenance headaches [5].
A common development approach – iterating for functionality without fully understanding the code – further compounds the problem. This "prompt-first" mindset often leads to shotgun surgery, where a single change impacts dozens of files because the original architecture lacked intentional design [3]. As one AI infrastructure developer from a Fortune 50 tech company noted:
"A junior engineer can write as fast as a senior engineer, but they don’t have the cognitive sense of what they’re doing… or what problems they’re causing" [4].
This lack of clarity doesn’t just make debugging harder; it also increases compliance costs as systems grow in complexity.
Higher Costs for Debugging and Compliance
The opaque nature of AI systems comes with steep financial and operational costs. Debugging becomes a monumental task when models can’t explain their decisions. AI failures are often silent, meaning the system might return a "successful" status while delivering hallucinated or biased results. Without interpretability, identifying and fixing these issues becomes a time-consuming and expensive process.
Compliance is another costly hurdle. Regulations like the EU AI Act and forthcoming US AI laws emphasize the need for transparency and explainability. If your system can’t justify its decisions – whether for loan approvals, medical diagnostics, or hiring recommendations – it poses serious compliance risks [9]. Tom Lucido from CloudFactory highlights the stakes:
"If optimization decisions… aren’t properly documented and auditable, organizations could face compliance gaps" [9].
With 75% of technology decision-makers forecasting that AI-driven complexity will push their technical debt to moderate or severe levels by 2026 [7], the financial burden of maintaining opaque systems is only set to grow.
AI’s Silent Killer: Technical Debt & the Hidden Costs of Bad Data
Data Dependencies and System Fragility
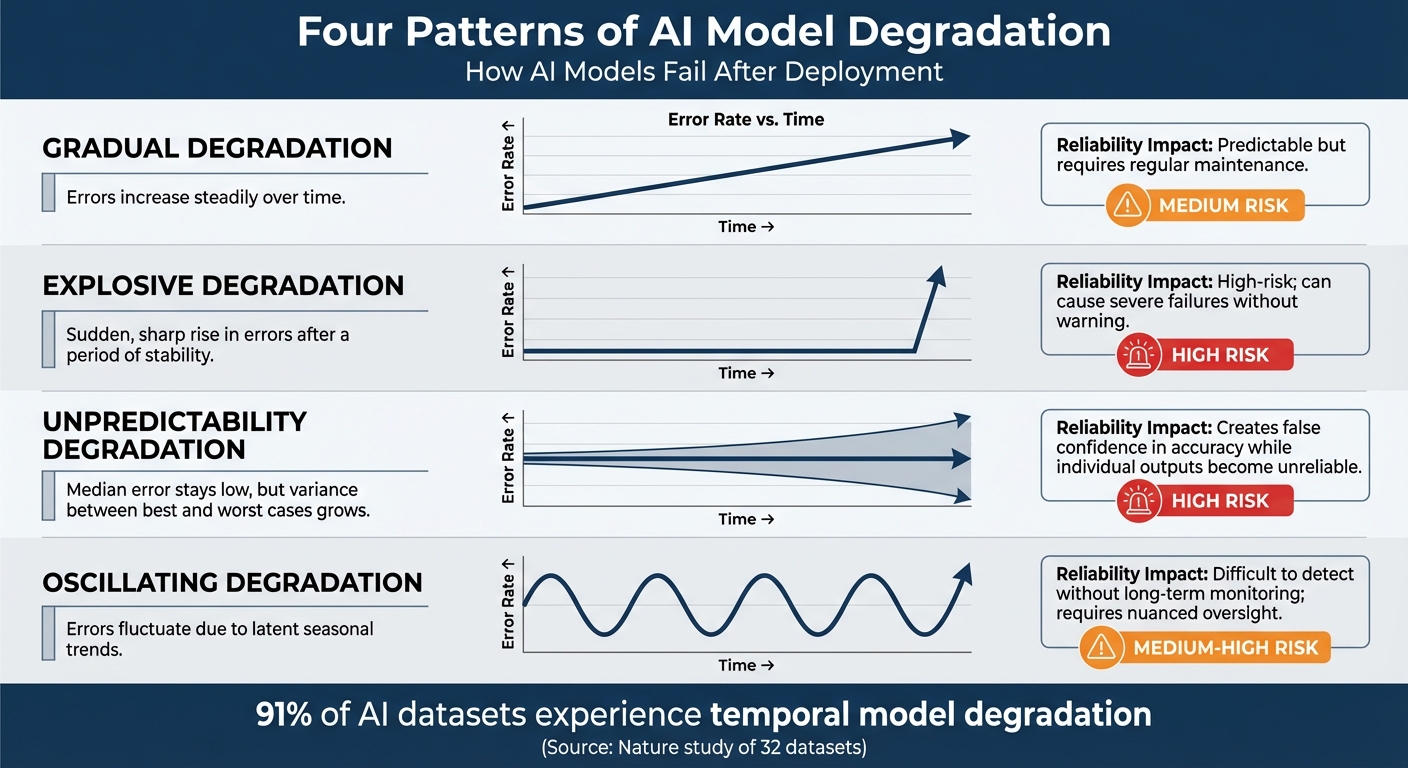
Four Patterns of AI Model Degradation Over Time
How Changing Datasets Affect Model Performance
AI models are deeply tied to the data they’re trained on, making them especially vulnerable to changes in that data. Unlike traditional software, where the behavior of the code remains stable, AI models depend heavily on data consistency. When real-world data shifts, the model’s ability to interpret its environment can falter, leading to what’s known as temporal degradation [10].
A study analyzing 32 datasets across industries like healthcare, transportation, finance, and weather found that 91% experienced temporal model degradation [10]. Even models that performed well during training, with R² scores between 0.7 and 0.9, often struggled after deployment due to subtle changes in data patterns [10].
This phenomenon ties into the CACE Principle, coined by Google researchers: "Changing Anything Changes Everything" [6]. AI systems operate as interconnected networks where even minor shifts in data distribution – or alterations to a single feature – can cause cascading failures throughout the system. The table below outlines common patterns of model degradation:
| Degradation Pattern | Description | Reliability Impact |
|---|---|---|
| Gradual | Errors increase steadily over time. | Predictable but requires regular maintenance. |
| Explosive | Sudden, sharp rise in errors after a period of stability. | High-risk; can cause severe failures without warning. |
| Unpredictability | Median error stays low, but variance between best and worst cases grows. | Creates false confidence in accuracy while individual outputs become unreliable. |
| Oscillating | Errors fluctuate due to latent seasonal trends. | Difficult to detect without long-term monitoring; requires nuanced oversight. |
The explosive degradation pattern is particularly alarming. A model might perform reliably for months before failing abruptly due to hidden variables or seasonal trends that only emerge under specific conditions [10]. As Daniel Vela and his team explained in Nature:
"The principal challenge in maintaining AI model quality stems from the very nature of the current ML models. Trained from and driven by data, these models become inherently dependent on the data as it was at the time of training" [10].
Data Quality as a Long-Term Liability
Shifts in data quality don’t just cause short-term performance issues – they create long-term challenges. Poor-quality data can accumulate technical debt over time, particularly in systems like Retrieval-Augmented Generation (RAG). These systems rely on components like embeddings, knowledge bases, and chunking strategies, all of which must be updated regularly to stay effective [6]. Unlike traditional machine learning models that work with static datasets, RAG systems demand continuous data curation to maintain their utility [6].
Overly complex data pipelines, often referred to as "pipeline jungles", exacerbate the problem [2][11]. A single broken link or formatting error can ripple through the system, making it difficult to identify and address the root cause.
Bias presents another hidden risk. Even models that pass fairness checks during training can develop new biases over time. As the significance of certain features – like age or gender – shifts, models may unintentionally introduce disparities [10]. This means fairness isn’t something that can be validated once; it requires ongoing vigilance.
And then there’s the financial cost. D. Sculley from Google aptly described machine learning as "the high-interest credit card of technical debt" [6]. What might seem like a quick win in the short term can evolve into a costly maintenance burden, diverting resources away from innovation and growth.
Model Drift and Performance Degradation
What Model Drift Means for Your System
Beyond data quality issues, model drift poses another challenge to maintaining AI performance over time. Model drift occurs when your AI system’s effectiveness declines because the environment it operates in has changed since the model was trained. Essentially, the patterns the model learned no longer align with the data it encounters in real-world scenarios. This is a natural limitation of AI systems.
What makes drift especially tricky is that it often hides behind outputs that appear valid. Mary Carmichael from ISACA‘s Emerging Trends Working Group explains it well:
"AI technical debt can hide behind ‘plausible’ model outputs, quietly building risk at the data and decision layer" [14].
In other words, your system might confidently produce results that are completely off-base, and without proper monitoring, these subtle issues can go unnoticed.
Consider the COVID-19 pandemic: machine learning models trained on pre-pandemic spending habits became unreliable as consumer behavior shifted dramatically [12]. Similarly, fraud detection systems frequently experience drift because fraudsters constantly adapt their methods to evade detection [12]. Unlike traditional software, where the code behaves consistently, AI models are driven by data, making them highly sensitive to environmental changes. These shifts, often invisible at first, demand ongoing intervention, leading to expensive retraining cycles.
The Cost of Continuous Retraining
Dealing with model drift requires constant vigilance – monitoring, retraining, and managing multiple model versions. Ana Bildea, PhD and Tech Lead AI, explains the challenge succinctly:
"Traditional technical debt accumulates linearly; AI technical debt compounds" [13].
What starts as a quick deployment can snowball into a major maintenance burden, pulling resources away from innovation.
The financial toll can be staggering. Organizations struggling with unmanaged model versions and drift often find themselves unable to release new features within 18 months [15]. According to a 2024 survey of 523 IT professionals, 74% of organizations report grappling with technical debt [12]. Yet, most allocate less than 20% of their tech budgets to addressing it [4].
The frequency of retraining depends on the application. High-stakes systems, such as those in healthcare or transportation, require frequent updates and human oversight. In contrast, text-based tools can often go longer between updates [12]. Still, every AI system demands some level of ongoing care. Daniel Vela and his team describe this phenomenon as:
"AI aging: the complex, multifaceted phenomenon of AI model quality degradation as more time passes since the last model training cycle" [10].
Another common issue is "versioning chaos", where different teams deploy various versions of models – some using GPT-4, others using Claude – without a unified strategy [13][15]. This lack of coordination drives up maintenance costs and complicates performance tracking across the organization. Paul Estes, Editor-in-Chief at Virtasant, emphasizes the importance of balancing priorities:
"Innovation has to be balanced with maintenance; for leaders, understanding the implications of technical debt in the context of AI models is crucial" [12].
When combined with earlier challenges like technical and epistemic debt, model drift underscores the critical need for proactive maintenance strategies.
sbb-itb-51b9a02
Integration Challenges with Existing Systems
Why Legacy Systems Struggle with AI
Integrating AI into legacy systems isn’t a walk in the park. In fact, over 90% of organizations face significant hurdles when trying to merge AI with their existing setups [17]. The root of the problem? Legacy systems were never designed to handle the demands of modern AI.
These older systems are often monolithic and inflexible, relying on outdated technologies like SOAP and XML. Such interfaces struggle to connect with AI services that depend on RESTful APIs and real-time data streams [17]. On top of that, many legacy systems operate on on-premise servers that lack the processing power to handle AI’s intense computational requirements. This mismatch leads to issues like system instability and high latency [17]. To make matters worse, enterprises typically dedicate 70% of their IT resources to simply maintaining these aging systems, leaving a mere 30% for innovation [17].
The challenges grow even more daunting when AI components are introduced into tightly coupled legacy code. Small changes in one area can trigger "shotgun surgery" – a scenario where hidden dependencies cause widespread disruptions [17][3]. Another major roadblock is the presence of data silos. When critical information is locked away in inconsistent or proprietary formats, AI models can’t access a unified "single source of truth" [17].
Looking ahead, the picture doesn’t get much brighter. By 2027, it’s predicted that over 40% of autonomous AI projects will be abandoned because legacy systems simply can’t support them [17]. A High Peak Software expert puts it bluntly:
"If you ‘integrate’ AI without addressing legacy limitations, you risk blowing up your roadmap with endless troubleshooting, rewrites, and delays" [17].
These outdated architectures not only complicate integration but also create new dependencies that make scaling even harder, piling on technical debt over time.
New Dependencies and Scalability Problems
Even after AI is integrated, it introduces a host of new challenges that strain scalability. For example, multi-agent AI solutions come with synchronization dependencies. If one AI agent fails, it can trigger a chain reaction, making it harder to pinpoint the root cause of the problem [16]. This interconnected behavior is a stark contrast to traditional software, where failures are usually isolated.
AI’s computational demands also add pressure. Poor token management and energy spikes can throttle system performance, drive up costs, and cause slowdowns during peak loads [16]. Another issue is the rise of inefficiencies in AI-assisted development. Studies show an eightfold increase in duplicated code blocks and a twofold rise in code churn, adding layers of complexity that make systems harder to maintain and less adaptable [4][3].
To avoid these pitfalls, some organizations allocate about 15% of their IT budgets specifically for addressing technical debt [1]. Without this proactive approach, the dependencies introduced by AI can turn systems into fragile structures – where even minor updates risk bringing everything crashing down.
How to Reduce AI-Related Technical Debt
Managing AI-related technical debt is entirely possible. By addressing challenges like black box models, data dependencies, and complex integrations head-on, startups can keep this issue under control. The key lies in treating AI systems with the same discipline as traditional software, while also accounting for their unique characteristics. A structured approach – complete with rigorous testing, monitoring, and human oversight – can help maintain stability throughout the AI lifecycle.
Using AlterSquare‘s I.D.E.A.L. Framework
AlterSquare’s I.D.E.A.L. Framework provides a step-by-step method to minimize long-term technical debt in AI systems. Here’s how it works:
- Discovery phase: This step identifies the critical 20% of the codebase responsible for 80% of issues. It also evaluates the overall technical health of the system, flagging potential legacy obstacles that may hinder progress [18][22].
- Design Validation phase: The focus here is on creating modular architectures and loosely coupled designs. By breaking down code and data into interchangeable components, teams can avoid common pitfalls like "Pipeline Jungles" (messy data flows) and "Glue Code" (fragile connections between components) [1][2][8]. This modular approach allows for easier updates and replacements without overhauling the entire system.
- Agile Development: During this phase, debt remediation becomes part of every sprint. Teams can allocate around 20% of sprint time to refactoring, using automated tools to detect and address issues in real time [1][19][21][22].
- Post-Launch Support: Ongoing monitoring is essential to catch problems like model drift, data anomalies, and performance dips. This phase also emphasizes human oversight and Explainable AI (XAI) to improve accountability and reduce maintenance costs [8][19].
Automated Testing and Performance Monitoring
For AI systems, manual testing just doesn’t cut it. Automated tools are a must. Integrate options like static code analysis and architectural health checks into your CI/CD pipelines to catch problems early [24]. Instead of focusing on the total volume of technical debt, measure technical debt density – this gives a clearer view of system health by showing how much debt exists per line of code [23]. Tools like SonarQube can help identify code-level issues, while platforms such as CAST can analyze structural weaknesses [24].
AI-specific monitoring also plays a crucial role. Research by Breck et al. outlines 28 monitoring tests designed to catch potential problems during the design phase [2]. Additionally, using dependency and call graphs can help pinpoint tightly coupled clusters or "debt hotspots" – areas where changes could cause widespread disruptions [24].
A study found that a 25% increase in AI usage led to a 7.2% drop in delivery stability, along with higher levels of code duplication and churn [4]. To break this cycle, automation must be paired with continuous vigilance. While automated tools can flag issues early, human oversight remains vital for interpreting results and ensuring model explainability.
Human Oversight and Model Explainability
AI can speed up code generation, but it often misses the bigger picture. Without proper management, technical debt can consume 20% to 40% of a developer’s time [18][19]. This makes human verification crucial. Use AI for initial drafts, but always have a person review the code to ensure it remains clear, testable, and well-structured. Rapid iterative coding – where quick AI-generated updates pile up – can lead to messy, unsound architecture that requires costly "shotgun surgery" to fix later. Junior developers are particularly susceptible to these risks [4].
Explainable AI (XAI) is a game-changer in this context. When your team understands why an AI model makes certain decisions, debugging and maintenance become much easier. Governance frameworks that prioritize explainability can reduce costs and improve accountability [8][19]. As Koenraad Schelfaut from Accenture points out:
"The stark reality is that with AI poised to penetrate every business function, all technical debt is becoming AI technical debt" [1].
The solution isn’t to shy away from AI but to approach it with awareness. Build cross-functional teams that include data engineers, machine learning engineers, and product managers. Evaluate new features using debt-adjusted ROI, factoring in modernization and integration costs upfront [20]. And always follow the "Boy Scout Rule": leave the codebase cleaner than you found it after every sprint [1].
Conclusion
AI has undeniably sped up innovation, but it also brings with it a hidden cost: technical debt that’s difficult to detect and expensive to manage. Issues like black box algorithms, fragile data dependencies, model drift, and integration hiccups can pile up, creating long-term liabilities that not only inflate maintenance costs but also slow down progress. In fact, the U.S. is grappling with a multi-trillion-dollar technical debt, and 79% of tech leaders now see this as a significant barrier to achieving their business goals [19]. Tackling this challenge requires a disciplined, strategic approach.
The key to managing AI effectively lies in understanding which debts to address, which to accept, and how to turn them into opportunities for innovation. As Koenraad Schelfaut and Prashant P. Shukla from Accenture explain:
"Addressing tech debt is not about eliminating it but managing it. The key lies in knowing what the debt is, what to fix, what to keep, and how to recognize the tech debt that is boosting your company’s innovation capacity" [1].
Successful companies treat AI challenges like any other engineering problem, using tools like automated testing, human oversight, and explainability to maintain control. Many forward-thinking organizations allocate around 15% of their IT budgets specifically for addressing technical debt [1]. This isn’t just an expense – it’s an investment in ensuring their systems remain scalable and maintainable over time.
Frameworks such as AlterSquare’s I.D.E.A.L. approach provide a structured way to manage these challenges. They help teams identify issues early, build modular systems, and continuously monitor performance. The ultimate goal is to strike a balance between speed and sustainability, enabling rapid delivery today without compromising tomorrow. While AI has the potential to boost developer productivity by up to 55% [4], this efficiency is only achievable when paired with the right safeguards.
To avoid letting technical debt weigh down your growth, focus on creating systems that are clear, testable, and manageable – paving the way for sustained innovation and operational efficiency.
FAQs
What is epistemic debt, and how is it different from traditional technical debt?
Epistemic debt refers to the knowledge gaps or unclear aspects within AI systems. This can include things like opaque decision-making processes, reliance on overly complex data, or hidden assumptions baked into the system. Unlike traditional technical debt – which typically involves outdated code or quick fixes that can be resolved through updates or refactoring – epistemic debt is less tangible and more tied to understanding and building trust in AI systems.
While technical debt is often straightforward to identify and address, epistemic debt poses unique challenges. It can lead to reduced explainability, make diagnosing problems harder, and even introduce compliance risks. Addressing it involves prioritizing transparency, maintaining thorough documentation, and committing to ongoing efforts to understand how AI models behave and evolve over time.
How can businesses manage AI model drift and ensure consistent performance?
To keep AI models performing consistently and avoid issues caused by drift, businesses need to focus on a few key practices. One of the most important steps is setting up continuous monitoring. By keeping an eye on critical metrics, teams can quickly spot drops in accuracy or unexpected changes in model behavior, allowing them to address problems as soon as they appear.
Another crucial step is conducting regular data audits. These audits help identify and fix issues like shifts in input data or quality problems that could lead to drift. Updating data pipelines as needed is also vital to ensure the model receives accurate and relevant information. On top of that, planning for model lifecycle management – which includes retraining or replacing models when they become outdated – helps maintain reliability over time.
By combining monitoring tools, regular audits, and a strong lifecycle management plan, businesses can stay ahead of changes and reduce the risk of accumulating technical challenges down the road.
How can AI be integrated into legacy systems without adding technical debt?
Integrating AI into legacy systems without piling on technical debt requires careful planning and sustainable strategies. A good starting point is to establish governance frameworks. These frameworks help track AI model performance, manage data dependencies, and ensure algorithm transparency. By catching potential problems early, you can avoid expensive rework down the line.
Equally important is aligning AI efforts with your existing software development processes. Treat AI components like any other software – apply rigorous testing, maintenance, and continuous monitoring. Leveraging automated tools during development can also help by flagging issues in real-time, keeping technical debt at bay. Additionally, having clear deployment standards ensures consistency and avoids common missteps.
With proactive management, smooth integration, and consistent oversight, you can harness the power of AI while keeping its impact on technical debt under control.







Leave a Reply